Key Features
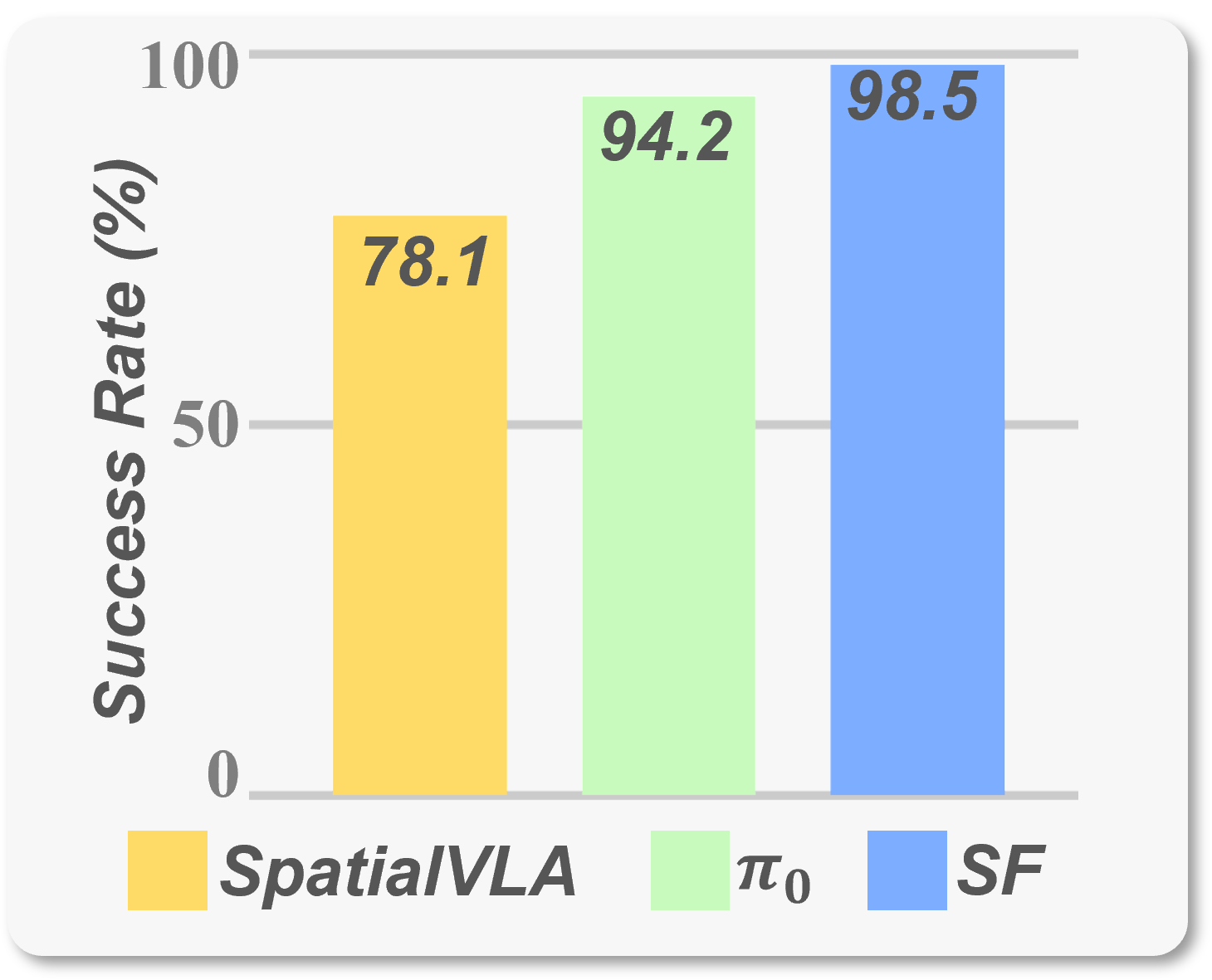
Performance
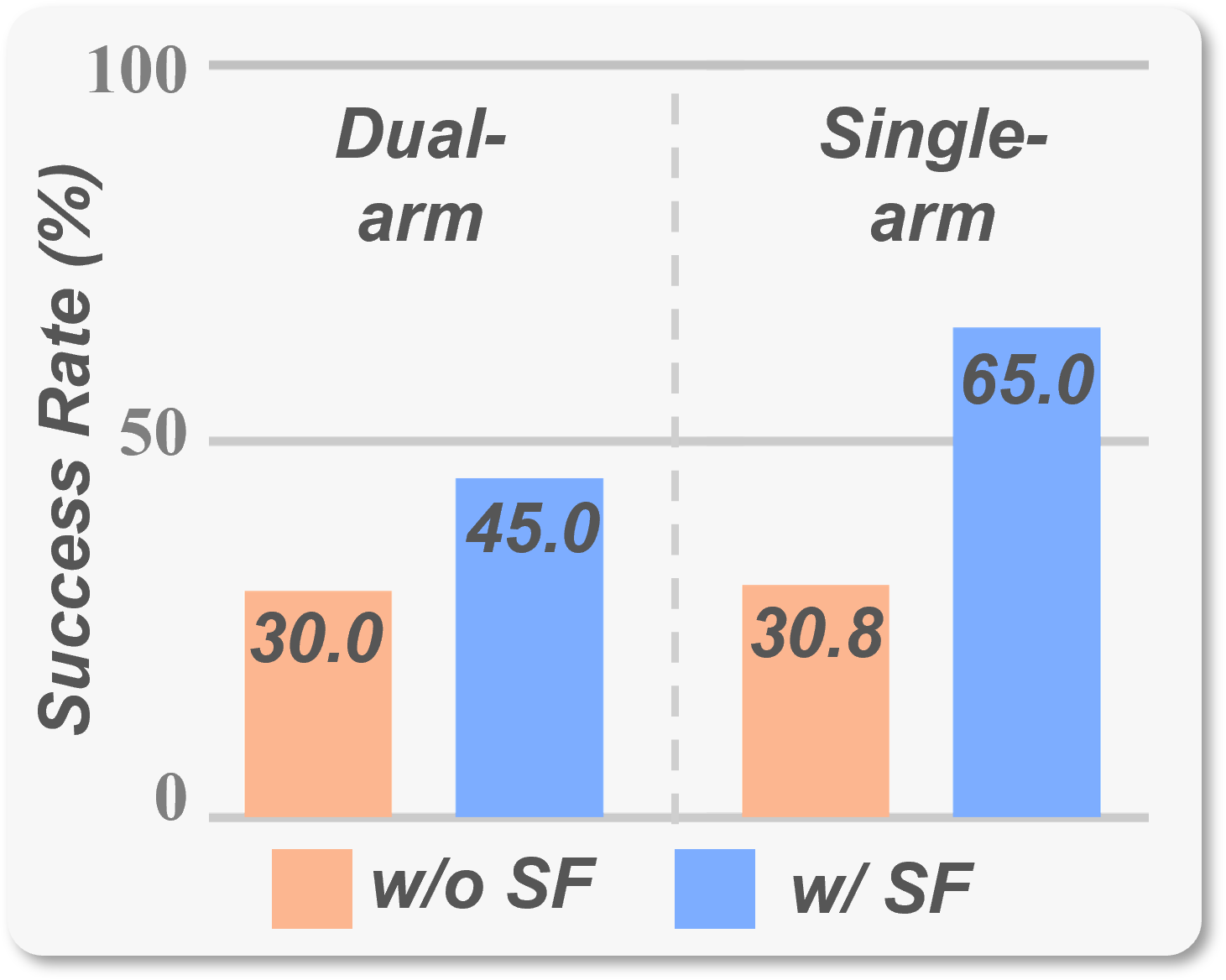
Performance
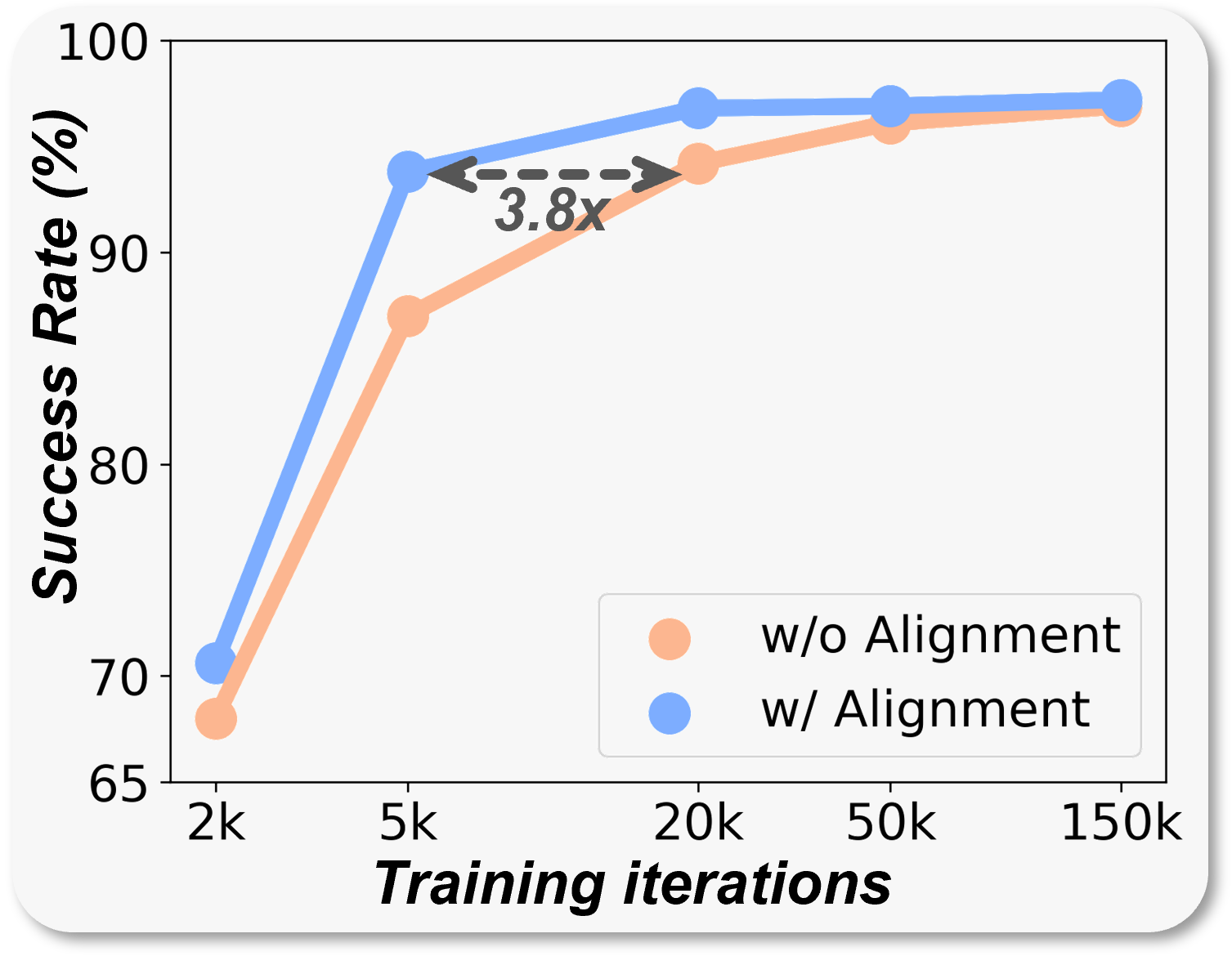
Efficiency
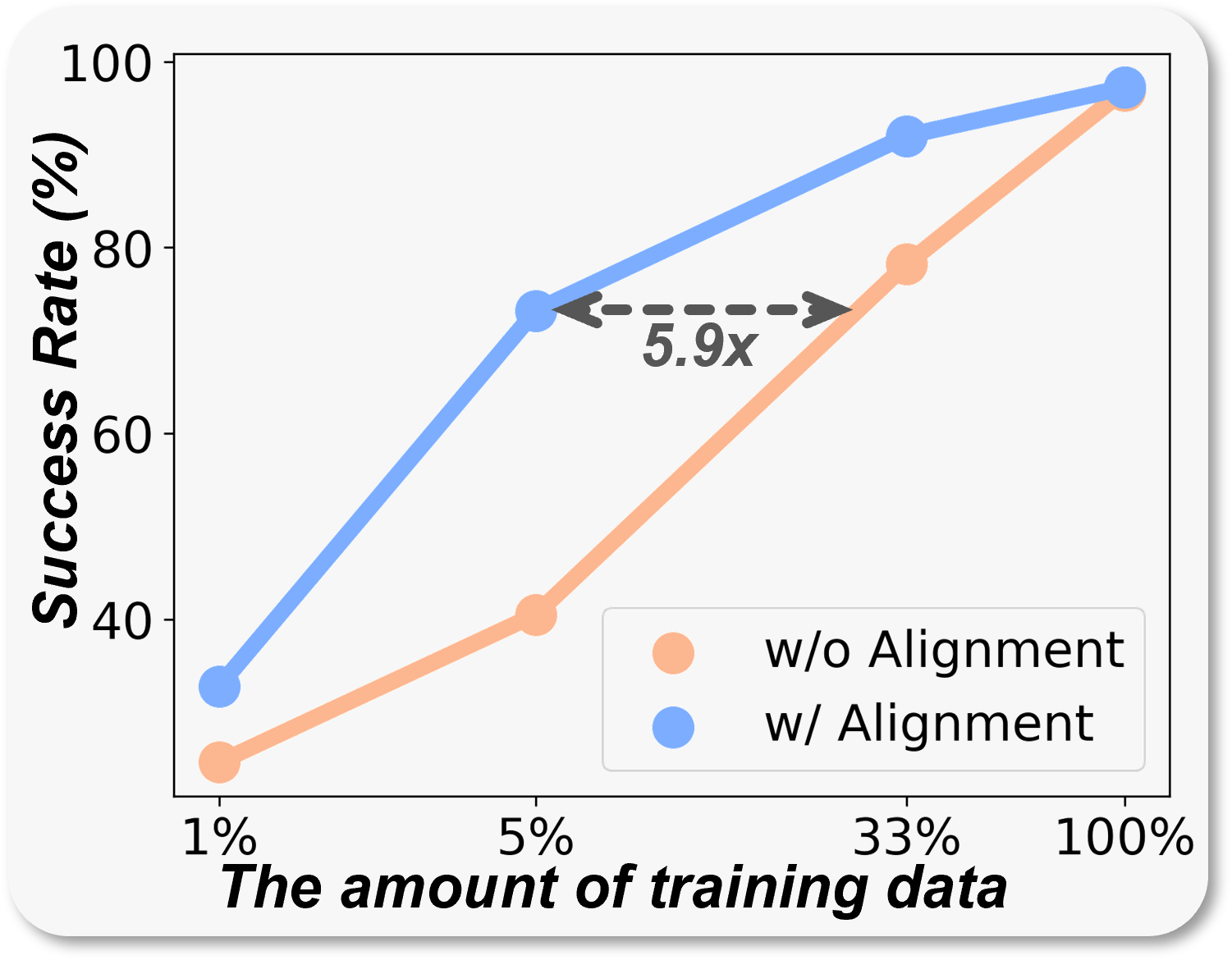
Efficiency
1. Universality: SF is a plug-and-play 3D finetune strategy that can be seamlessly integrated with any VLA training process, requiring only minimal code modifications with 30 lines. It substantially enhances spatial reasoning and manipulation capabilities. We provide implementations based on OpenVLA and Pi0, along with a quick-start guide for adapting SF to other VLA models.
2. Strong Performance: SF achieves state-of-the-art (SOTA) results on both LIBERO and RoboTwin benchmarks. In real-world experiments involving complex spatial structures, SF improves task success rates by up to 50%.
3. Efficient Training: SF requires only 3% of the training steps or 5% of the training data to reach a 66% success rate on LIBERO-Long. Moreover, it achieves strong real-world performance with as few as 20 demonstrations.
Abstract
Vision-language-action (VLA) models have recently shown strong potential in enabling robots to follow language instructions and execute precise actions. However, most VLAs are built upon vision-language models pretrained solely on 2D data, which lack accurate spatial awareness and hinder their ability to operate in the 3D physical world. Existing solutions attempt to incorporate explicit 3D sensor inputs such as depth maps or point clouds, but these approaches face challenges due to sensor noise, hardware heterogeneity, and incomplete depth coverage in existing datasets. Alternative methods that estimate 3D cues from 2D images also suffer from the limited performance of depth estimators. We propose Spatial Forcing (SF), a simple yet effective alignment strategy that implicitly forces VLA models to develop spatial comprehension capabilities without relying on explicit 3D inputs or depth estimators. SF aligns intermediate visual embeddings of VLAs with geometric representations produced by pretrained 3D foundation models. By enforcing alignment at intermediate layers, SF guides VLAs to encode richer spatial representations that enhance action precision. Extensive experiments in simulation and real-world environments demonstrate that SF achieves state-of-the-art results, surpassing both 2D- and 3D-based VLAs. SF further accelerates training by up to 3.8x and improves data efficiency across diverse robotic tasks.
Method
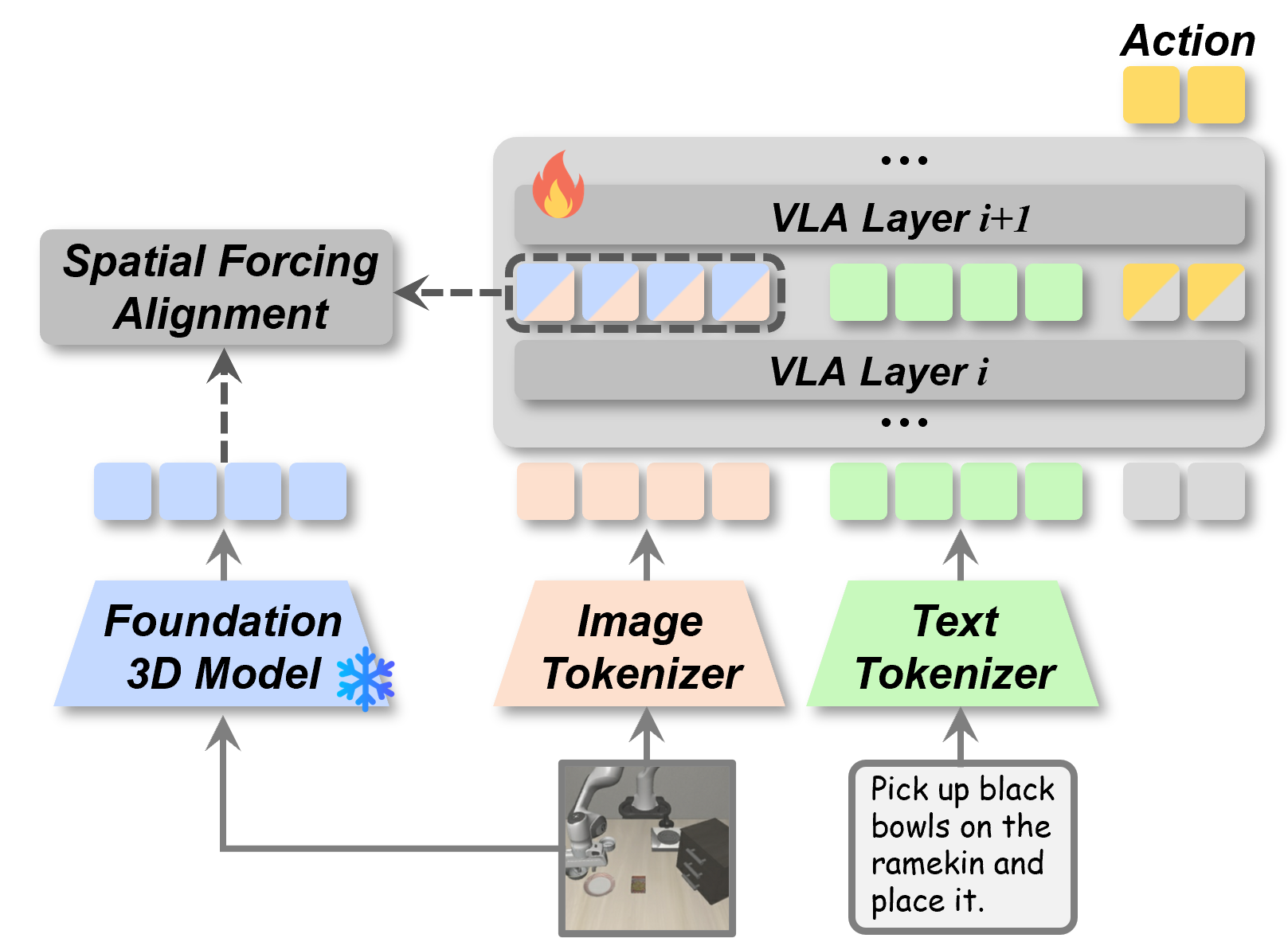
Our core philosophy is to enhance the model's spatial awareness using an external guide. To provide our model with a rich understanding of 3D space, we leverage a powerful, pre-trained 3D foundation model VGGT. For any given set of multi-view images, this foundation model generates detailed, pixel-level spatial representations—effectively creating a 3D-aware feature map from 2D inputs. These representations are further enriched with positional embeddings to maintain critical structural information.
The key to our method is aligning the VLA's own visual tokens with these high-quality 3D signals. To achieve this, we first process the VLA's internal visual features through a normalization layer and a small neural network (MLP) to ensure their format is compatible with the 3D representations. We then train the model to maximize the cosine similarity between its own processed visual tokens and the corresponding 3D spatial signals from the foundation model. This alignment process effectively forces the VLA to learn and internalize a much deeper understanding of 3D geometry, directly from 2D images.
Experiments
Evaluation on LIBERO Benchmark
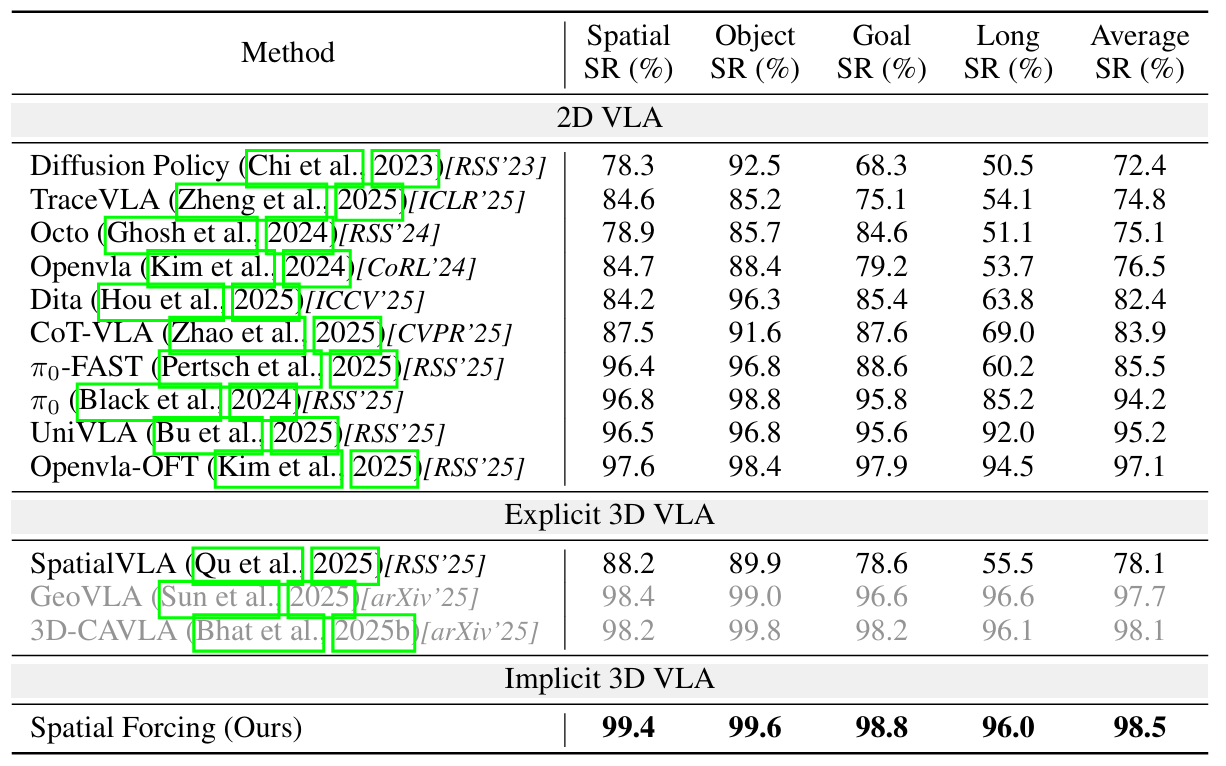
Spatial Forcing gets the best performance across all four tasks. Specifically, strictly following the same setup of OpenVLA-OFT to use both primary and wrist camera images, our method outperforms them quite a lot.
Evaluation on RoboTwin 2.0 Benchmark
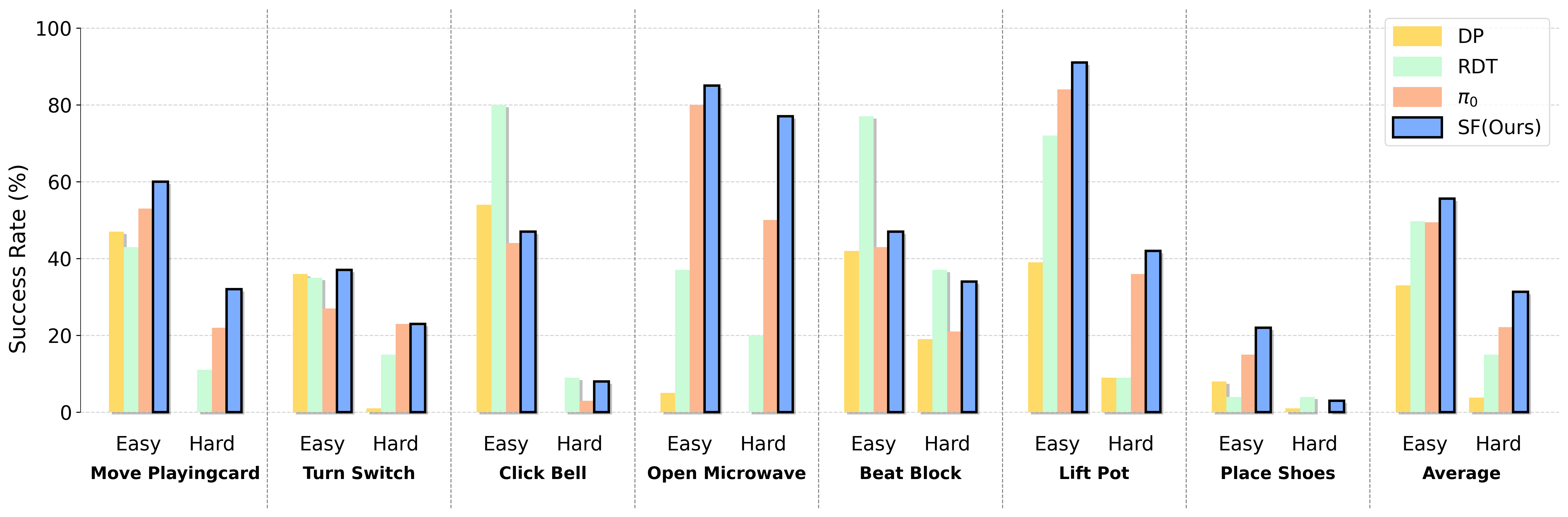
Spatial Forcing achieves the highest average success rate and yields substantial improvements over the base model π0 across all tasks, which demonstrates its effectiveness in enhancing the spatial awareness.
Evaluation on Real World

BibTeX
@article{spatialforcing2025,
author = {Li Fuhao, Song Wenxuan, Zhao Han, Wang Jingbo, Ding Pengxiang, Wang Donglin, Zeng Long, Li Haoang},
title = {Spatial Forcing: Implicit Spatial Representation Alignment For Vision-Language-Action Model},
journal = {arXiv preprint arXiv:2510.12276},
year = {2025},
}